Excel and CSV file upload
You can upload data from Excel and CSV files to eazyBI and then create reports, charts and dashboards from these data.
First, read about eazyBI cubes, dimensions, and measures – you will need to understand the multi-dimensional data model to map source file columns to cube dimensions and measures.
On this page:
Upload files
Go to the Source Data tab Source Files and choose the source file from the local directory or server for upload.
Source column mapping
After uploading the file, click Preview to proceed with file column mapping and create the data cube.
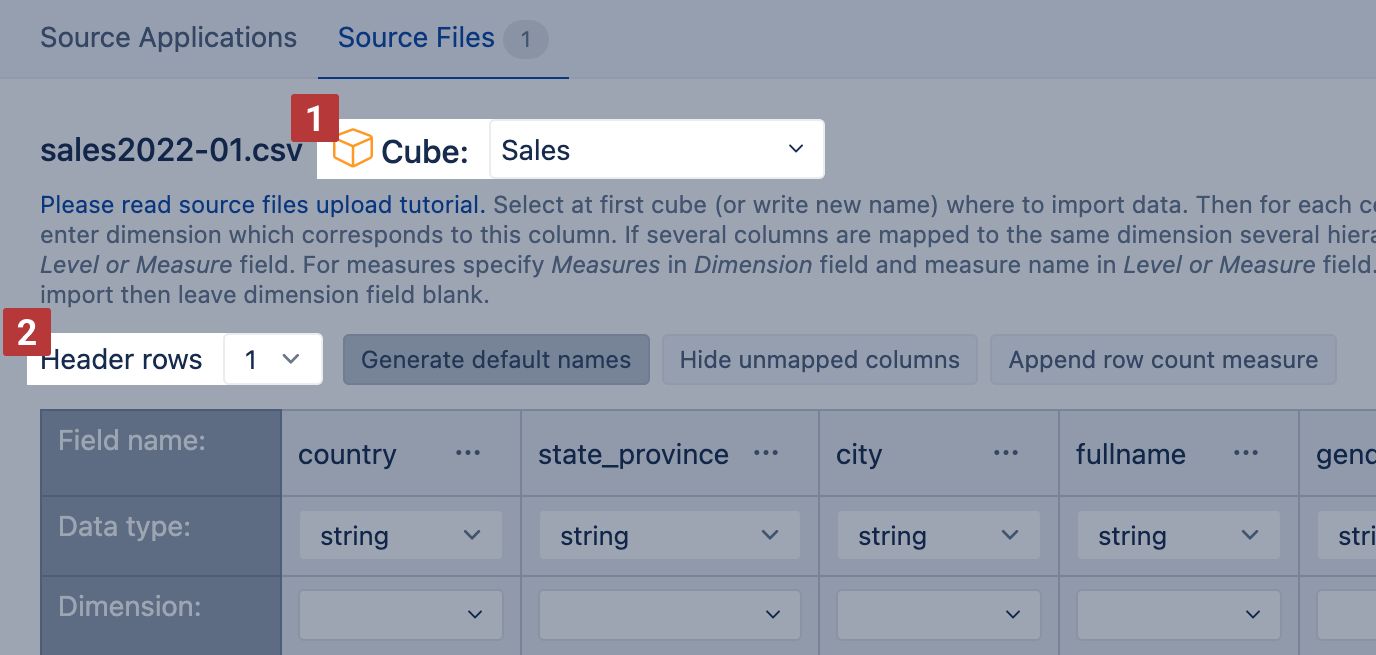
First, enter the data cube name where you would like to import your data [1]. If this is new data set, then enter a new cube name, for example, Sales cube, for importing sales transactions. You can also import a new file in the existing data cube to add a new data set or additional data – in this case, select the existing cube name.
eazyBI detects if a file has a header row with column names [2]. If eazyBI has detected it incorrectly, you can change the number of header rows. For example, specify 0 if you do not have any header row. You might want to check the heater row before mapping columns, as this reloads the file on the screen.
eazyBI will try to detect each source file column data type based on the first 100 rows of the source file. Detected column types (string, integer, decimal, date, or datetime) are shown below each column name. If some column type is detected incorrectly, then you can change it. For example, change from integer to string if this column might also contain non-integer values or contains a numeric identifier that, by nature, is descriptive information. Or change DateTime to Date if you only import the date without a time component.
If you upload a CSV file
- Use the comma
,or semicolon;as a field separator in the file. - Use the period
.as a decimal separator. Commas,in integer and decimal values are ignored if they are used as a thousand separator. - eazyBI recognizes only specific Date and DateTime formats. If you upload a CSV file, ensure the date is written in the supported date format.
- If the source CSV file contains non-English characters, then the CSV file should be in UTF-8 encoding. Otherwise, you might receive error messages when previewing the uploaded file.
If you upload an Excel file
- eazyBI allows data import from the first sheet of the Excel file.
- Integer, decimal, and date fields will be detected based on Excel cell formatting.
- If your original non-English data are in Microsoft Excel, then upload these Excel files as Excel export to CSV does not support UTF-8 encoding.
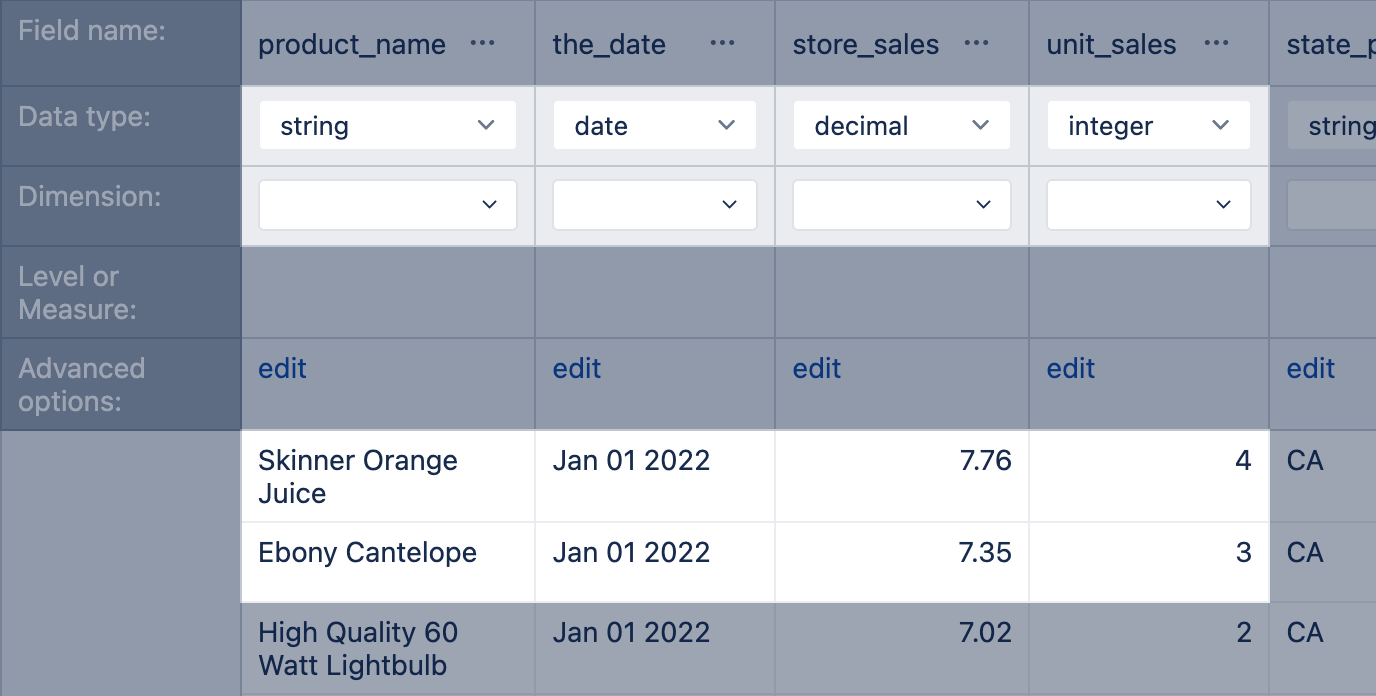
Now you can proceed with data mapping. The basic concept is to map at least one column with string data type mapped as a dimension and at least one column with numeric values (integer or decimal) as a measure. Please see data mapping for data mapping rules and how to map each column to measure dimension or property.

Start import
When you have completed columns mapping to dimensions and measures, click Start import to import source file data into the specified data cube. If there is any missing information in the source file columns mapping, then you will get an error message about missing information, and columns with errors will be highlighted with a red frame so you can see where to adjust the mapping.
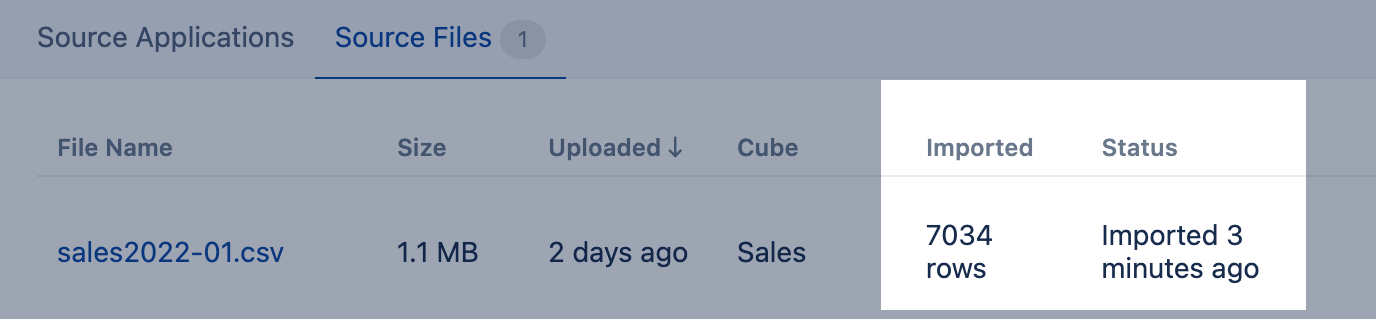
If there are no column mapping errors, then source file import will be started in the background, and you will see the file import status and count of imported rows which will automatically refresh.
Changes in file
You can replace the successfully imported source file with the updated file version. For example, some records in the original file are updated, or new lines with more recent data are added. Then you can keep the file name and upload the updated file version again; during the upload, eazyBI will ask for confirmation that you want to replace the uploaded file. After the file is uploaded (replaced), click Preview to check on file content and mapping and proceed with data import. Click Start import to import data from the source file, eazyBI will delete all previously imported data and replace them with data from the latest uploaded file version.
See the chapter Import additional source files with the same structure for an alternative way to import new data with the same structure.
If the changes in the file require new columns or changes in data mapping (rename dimension or measure or change data type for some column), then please see the next chapter Changes in data mapping.
Changes in data mapping
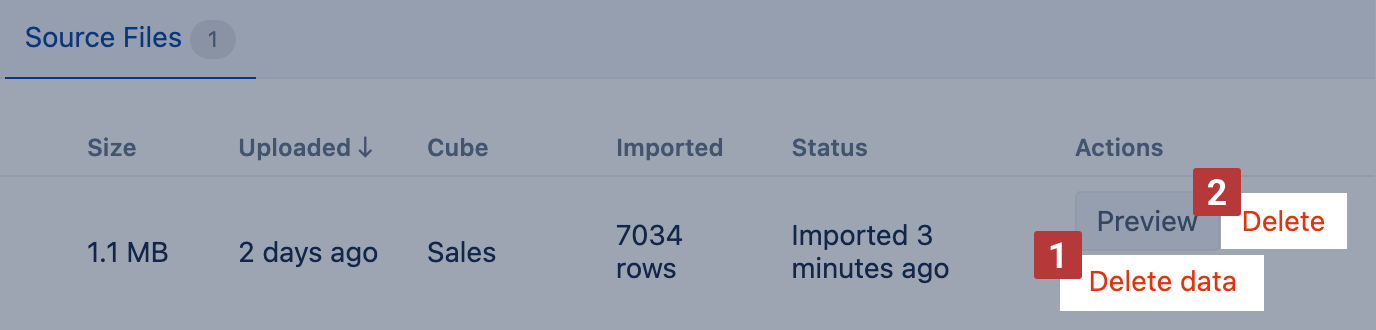
Correct data mapping sometimes requires several tries with some fails before you get the correct result; for example, you would like to change the dimension or measure names, reorganize the hierarchy, change data mapping for a date field, or add more columns to data mapping. The recommendation is to start from a clean sport and delete previously imported data.
You can Delete data [1] to adjust the data mapping for the same file. Or you can choose the option Delete [2] to delete the file and data to get rid of imported data altogether.
See also the documentation on how to make changes in data mapping.
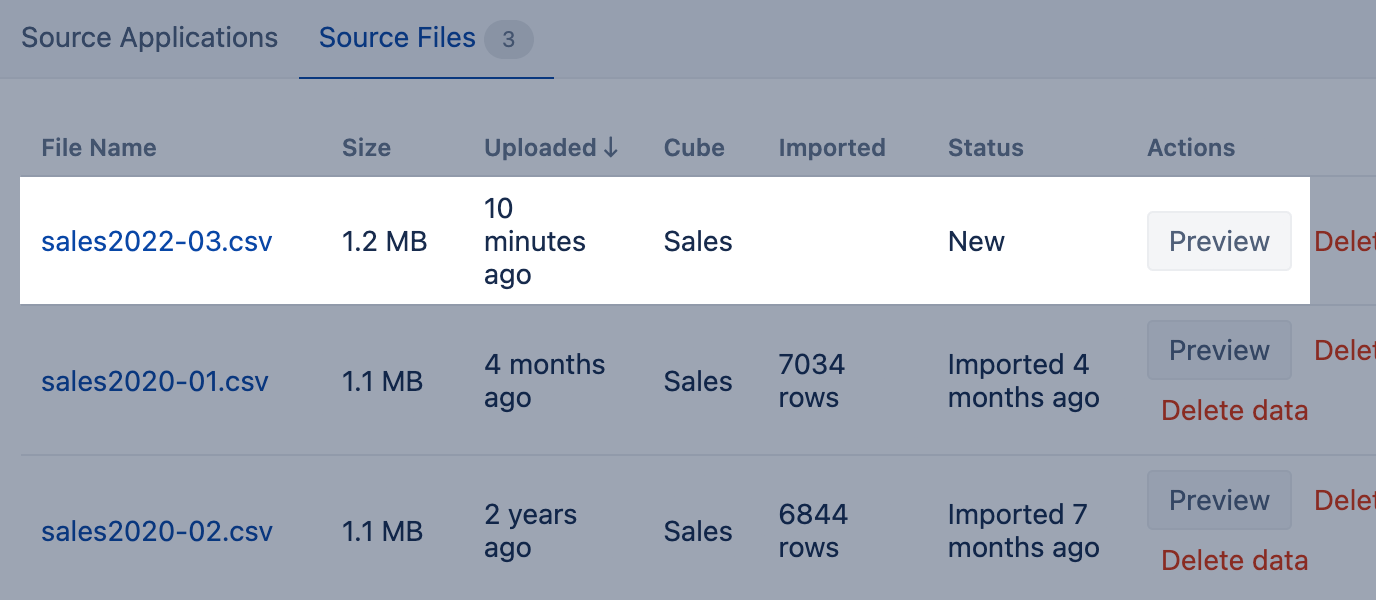
Import additional source files with the same structure
If you import additional data with the same source file structure (same column names and data types) as the existing imported file, then use a unique file name for each file. For example, if you would upload new data for the last month then it would make sense to add the year and month to the file name or sequence so you and ezyBI could set them apart.
After clicking Preview, eazyBI copies column mapping from the already imported file. And you can import the new file right away by clicking Start import.
Give a unique name for the dimension if the field must be mapped as a new dimension.
Import additional measures in source application cubes
If you are using eazyBI standard integration with other source applications (e.g., Basecamp, Highrise, Jira, Zendesk, or Harvest) but would like to add additional measures to your source application data cubes. It is possible to import additional measures from CSV files in existing source application data cubes.
But there is also a risk that you will not correctly prepare additional data in CSV files which may result in damaged existing source application data. Please view the additional data import example for Jira Issues cube. If necessary, contact eazyBI support and describe your need, and we will help you prepare CSV files correctly with additional data.