Import from SQL
You can import data from a specified database connection and using SQL SELECT statement result data. Data import is similar to Excel and CSV file upload and Import from REST API. You can also schedule regular daily import from provided SQL SELECT statement results.
Please at first read about eazyBI cubes, dimensions and measures - you will need to understand the multi-dimensional data model to be able to map source file columns to cube dimensions and measures.
On this page:
Create new source application
Go to Source Data tab and Add new source application and select SQL application type.

If you have already created another similar SQL data source, then you can export its definition and paste it in Import definition to create a new SQL source application with the same parameters.
SQL source parameters
In the next step, you will need to provide SQL source parameters that will be used to retrieve the data. See example:
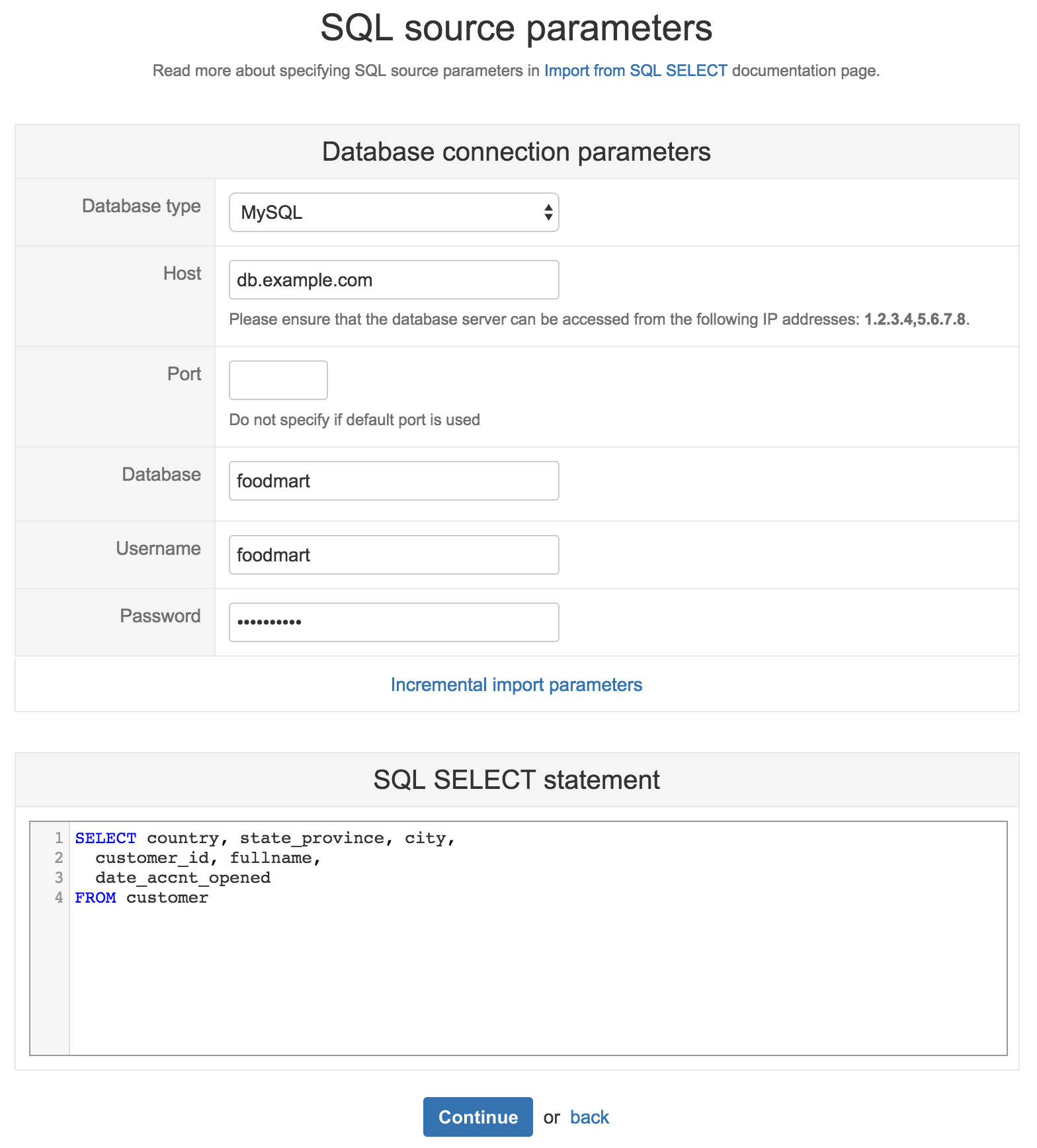
In Database type, select database server type – MySQL, PostgreSQL, MS SQL, and Oracle are supported. If you want to import data from the Oracle database and do not find this option, please add the Oracle JDBC driver ojdbc8.jar to the server (for more details, see Database connection setup on eazyBI for Jira or database setup on Private eazyBI).
In Private eazyBI, you can also select Generic JDBC database type and specify the JDBC driver class name and JDBC URL. Please copy the corresponding JDBC driver jar file to eazybi_private/lib directory and restart Private eazyBI after that.
Specify database server Host and optional Port parameter (depending on the selected database type, some other optional parameters might be available). Specify the Database name and database Username and Password that should be used. For Oracle database in the Database name field, provide database SID or Service Name (prefix service name with "/" - /SERVICE_NAME).
Enter SQL SELECT statement, which should be used to retrieve the data. Before SQL SELECT statement, you can add SQL comment (either start line with -- or enclose in /* and */) and then this comment will also be shown in the Source Data source applications list (can be useful if many SQL SELECT sources are used in the same account).
Incremental import
By default, SQL import will always re-import all data. During the import, the old imported Measures data will be deleted and then replaced by newly returned Measures data. Dimension members will be updated, and new Dimension members added. Note old Dimension members are not deleted. If SQL SELECT returns many rows, then each data import might take a long time as well as reports might return incomplete data while the old data are deleted, and not all new data are imported.
If you would like to use incremental import to update just the recent source data after the initial full import, then click Incremental import parameters and enable it:
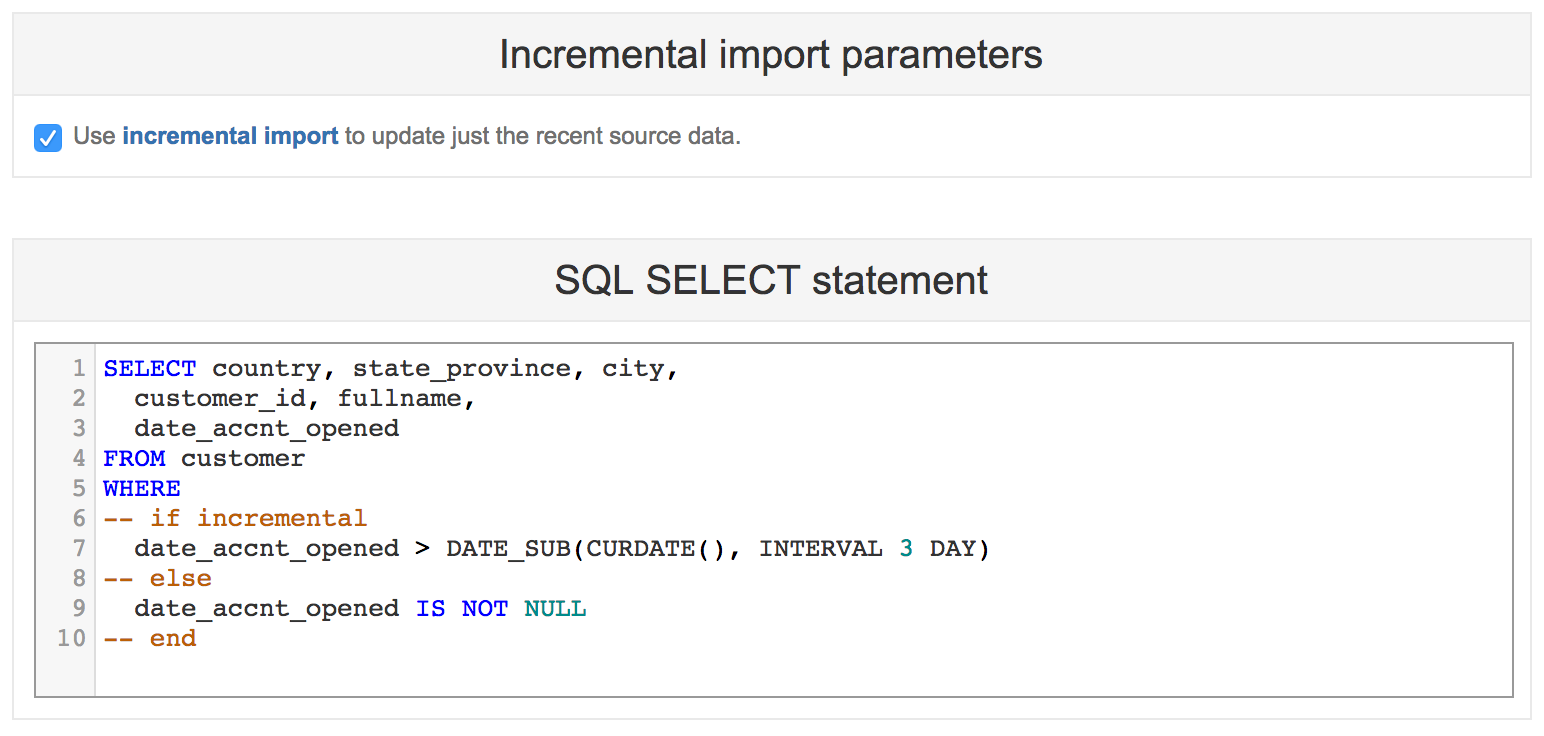
(example for MySQL database, change SQL conditions according to your database)
In addition, specify the incremental import WHERE conditions in the SELECT statement. Use special -- if incremental, -- else, -- end comments (as shown in the example) to specify which lines should be included only for the incremental import and which lines only for the full import. Typically you need to specify a condition that filters just recently updated rows using the corresponding date column.
If an incremental import is used, then it will be required to specify a Source ID column in the source columns mapping step. Source ID column value should provide a unique results row identifier. It is used to identify when some existing imported rows in eazyBI should be replaced with updated source data during the incremental import.
If you have previously imported all data without the incremental import option, then it will not be possible to modify the source columns mapping. Therefore, at first, delete all imported data for this SQL source, and then modify the source columns mapping and specify the Source ID column.
Source columns mapping
SQL source columns mapping is similar to Excel or CSV file columns mapping and Import from REST API. Please review these documentation pages to learn more about columns mapping to eazyBI dimensions and measures.
See an example of SQL SELECT columns mapping:
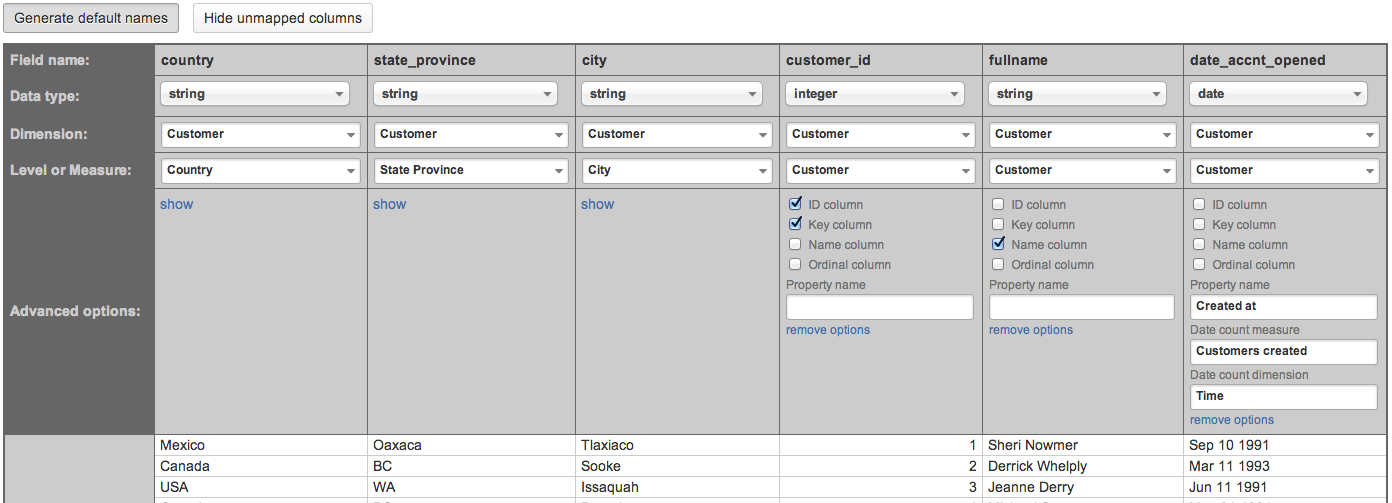
After mapping all necessary columns, you can click Start import. If there will be any mapping errors, then they will be shown, and columns with errors will be highlighted. If you need to save a draft of mapping, then click Back to edit and confirm that you want to save changes.
Importing of source data
If source columns mapping was saved without any validation errors, then SQL source application will be queued for background import. You will see the updated count of imported rows during the import:

You can later visit the Source Data tab again and click the Import button again to import the latest data from the SQL source. During each import, it will at first delete all data that were imported previously from this source and then import new data. In addition, you can also click Delete data to delete imported data from this source (you need to delete imported data also if you want to change source columns mapping).
Export definition
As it was mentioned in the beginning, you can export SQL source application definition by clicking Export definition from Source Data tab source application listing and then copy this definition and paste in Import definition field when creating different source application.