Dedicated nodes for Data Center
eazyBI for Jira
eazyBI for Confluence
The latest eazyBI version includes improved Jira Data Center support which allows to configure eazyBI load across different cluster nodes.
On this page:
Overview
Previous eazyBI versions (when used in a Jira Data Center cluster) distributed eazyBI load randomly across the cluster nodes. The incoming eazyBI report execution requests were performed on a node where the web request was distributed by the load balancer. The background import jobs were randomly executed on some cluster nodes. Many Jira Data Center customers preferred to specify which Jira Data Center cluster nodes are used for CPU and memory intensive eazyBI tasks to minimize the performance impact on other nodes.
The new improved eazyBI for Jira Data Center allows to specify dedicated nodes of the cluster where complex eazyBI tasks (report execution and background import jobs) are executed:
- User requests are distributed to cluster nodes by the load balancer. Each node is running an eazyBI instance which accepts the eazyBI report requests but then makes a proxy request to one of the specified eazyBI dedicated nodes.
- The eazyBI dedicated node performs the report request in a separate eazyBI child process and then returns report results to the original request node.
- Both manually initiated as well as scheduled import jobs are executed only on eazyBI dedicated nodes.
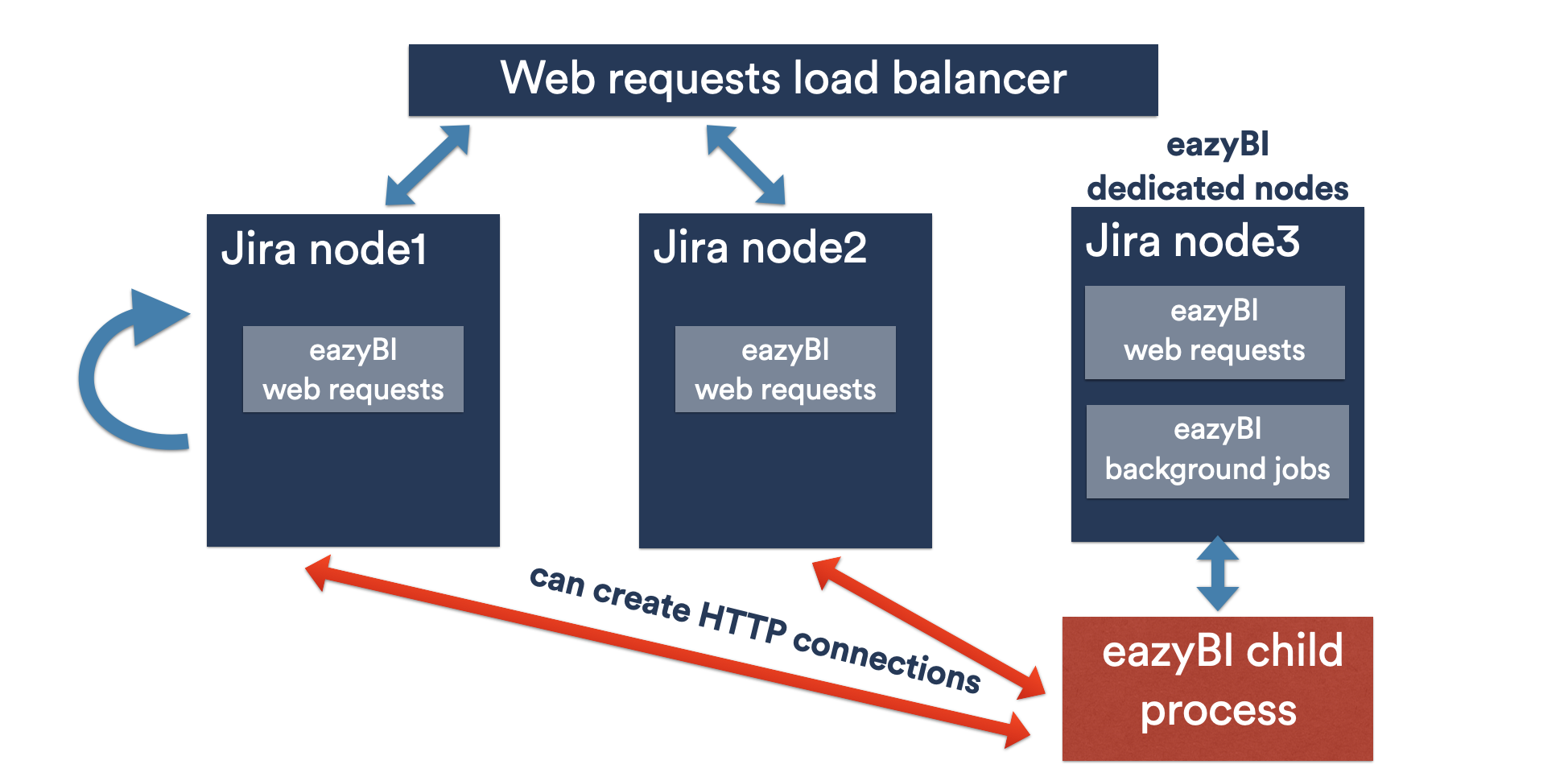
For large Jira Data Center installations it is recommended to have a separate cluster node (or several nodes) that are not used by the load balancer for incoming user requests. This separate node can be used both as an eazyBI dedicated node as well as for other non-user request purposes. In this case, when eazyBI will execute complex requests and perform long data imports it will not affect the performance of other nodes that handle incoming user requests.
Settings
When eazyBI is installed in Jira Data Center then the eazyBI settings page (where you initially specify the database connection) will show a separate Data Center section.
Dedicated nodes
Select from the list of available cluster nodes which should be used as eazyBI dedicated nodes.
Typically, just one dedicated node is enough, but for large Jira Data Center installations, you can specify several dedicated nodes.
You can also specify (all nodes) if you would like to use all nodes as dedicated eazyBI nodes (this typically is only used when the list of Data Center nodes are changing dynamically all the time).
Child process
The eazyBI child process will be started only on specified dedicated nodes.
Specify additional JVM options if needed (for example, to increase the child process JVM heap max memory).
If several dedicated nodes are specified, then a random node will be selected for each new incoming user request. A selected child process node is cached for 5 minutes for each user (so that sequential requests from the same user are directed to the same dedicated node).
The list of dedicated nodes is stored in the Jira shared home directory in the eazybi.toml file, where database connection and child process parameters are stored as well.
If the list of eazyBI dedicated nodes is updated, then eazyBI instances on each node reconfigure themselves automatically (start or stop the child process and start to process background jobs).
Separate background job nodes
Dedicated nodes for data import jobs is available since eazyBI version 8.2.
By default, dedicated nodes handle both report execution and background job processing. For advanced setups requiring further workload separation, eazyBI supports separating these workloads across different node sets.
Add the following configuration in the Advanced Settings to enable separate nodes for background jobs:
[job_queue] separate_nodes = true
When enabled, the Data Center configuration page will show an additional node selection option.
Background job (data import) nodes handle data imports, scheduled tasks, and other background processing (new selection appears when the feature is enabled).
Important notes:
CRITICAL: Feature takes effect immediately - you must immediately configure background job nodes after enabling, or all background jobs will fail
No restart required - configuration changes apply instantly
Both node types must have at least one active node selected
If background job nodes become unavailable, imports will fail until nodes are restored
Can be disabled by removing or setting
separate_nodes = falsein advanced settings
Log files
Possible issue with NFSv3 mounts
eazyBI is relying on command flock and this command may ‘freeze’ when accessing files on the NFSv3 mount if this mount and file locking infrastructure are not properly configured. We recommend using NFSv4 instead of v3 for Jira Shared Home mounts. In case when NFSv3 is the only available option for Jira Shared Home mounts please validate if the flock is working correctly.
On all Jira nodes please execute these two commands (please update the path to Jira shared home folder)
touch <JIRA_SHARED_HOME>/test_file flock <JIRA_SHARED_HOME>/test_file -c 'sleep 1'
If the flock command will run as expected it will finish after a few seconds. If it ‘hangs’ (more than 10 seconds) then it is not working properly. The most common reason for that is a firewall blocking ports used for file locking.
The latest eazyBI version stores all log files in the shared Jira home directory (the previous versions stored the log files in local Jira home directories of each node). This change was made to enable that log files can be accessed from each node and enable to create a zip file with all logs for support and troubleshooting purposes.
Each log file name will contain a suffix with the node name which created this file (see the NODE placeholder below). The following log files will be created in the log subdirectory of the shared Jira home directory:
eazybi-web-NODE.log– the main log file with incoming web requests.eazybi-queues-NODE.log– the log file for background import jobs (on dedicated nodes).eazybi-child-NODE.log– the log file for the child process (on dedicated nodes).
Troubleshooting
The system administration Troubleshooting page can be used to:
- See the status of the child process on the dedicated node.
Starting from the version 4.7.2, Response from host will show from which child process node the status is returned.
If you will press Restart then child processes on all dedicated nodes will be restarted. Use Restart only when you get errors about the child process unavailability or unexpected slow performance and check if the performance is normal again after the restart. - See the list of all log files from all nodes, see the content of these log files as well as download a zip file with all log files.
Child process and background job log files are shown only for active dedicated nodes.
The system administration Background jobs page can be used to see the status and statistics of background jobs processing on dedicated nodes. Each queue name has a node prefix indicating on which node this queue is processed. The size of background job queues can be modified in the eazyBI advanced settings.