Sprint reports for sprint week cycles (Sprint custom hierarchies)
eazyBI for Jira
The following examples will show how to build the most popular Sprint reports for sprint cycles. Sprint cycles are parallel (or treated as parallel) sprints you want to analyze as one entity. Sprint cycles can be formed based on the same sprint start (end) date or a sprint naming pattern (sprint sequence number in the sprint name).
The following example is based on the Sprint start date week: all sprints started in the same week are treated as one sprint cycle and will be analyzed as one in sprint reports.
On this page:
Import Sprint property Week cycle
To define the sprint cycle based on the sprint start date week, import the week related to the sprint start date as a sprint property "Week cycle". Use any of the additional data import options to import this property: from a file, SQL select, or using Jira REST API for retrieving sprint information.
The following is an example of Jira Sprint REST API import to import sprint week cycle as a property, based on the retrieved sprint start date from Jira.
In Source Data (where you already have Jira as a data source), select “Add new source application”. Chose the option to “import definition” and paste in the code below:
This REST API import retrieves two columns: Sprint ID and sprint start date week. To get the sprint week, JavaScript is used to convert the sprint start date value to the week in a format "yyWnn, mm dd yyyy" (example: 21W35, Aug 30 2021).
When importing the REST API import definition, adjust the REST API source parameters (URL, authentification) to match your Jira instance (https://docs.eazybi.com/eazybi/data-import/import-from-rest-api#ImportfromRESTAPI-RESTAPIsourceparameters 6)
You will import those data into the Jira issue cube. Map data to Sprint dimension Sprint level by sprint ID. Use option "Skip missing" to avoid import errors if there is no such sprint imported into the particular account. Import sprint week as a property for this Sprint dimension Sprint level members, name it Week cycle. Start import.
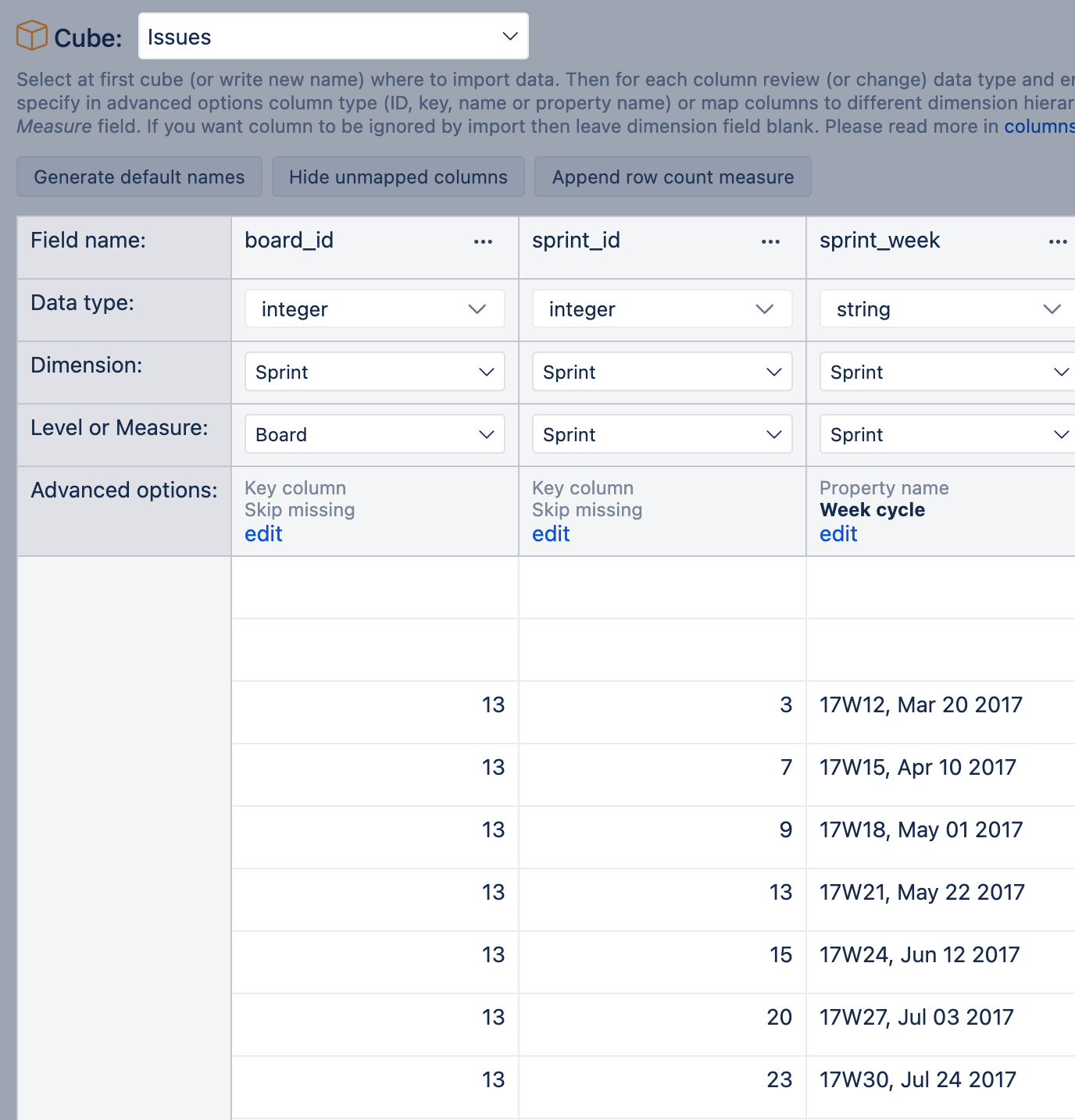
To use the following report examples without additional processing, the sprint week cycle property must be in the format "yyWnn, mm dd yyyy" and a sprint property name "Week cycle"; both are used in further calculations.
Create Sprint custom hierarchy by Week cycle
When the sprint property is imported, create a custom hierarchy in the Sprint dimension based on this property. In the Sprint dimension All hierarchy level members section click "Add custom hierarchy" [1] and then, in the dialog screen, select property "Week cycle" [2].
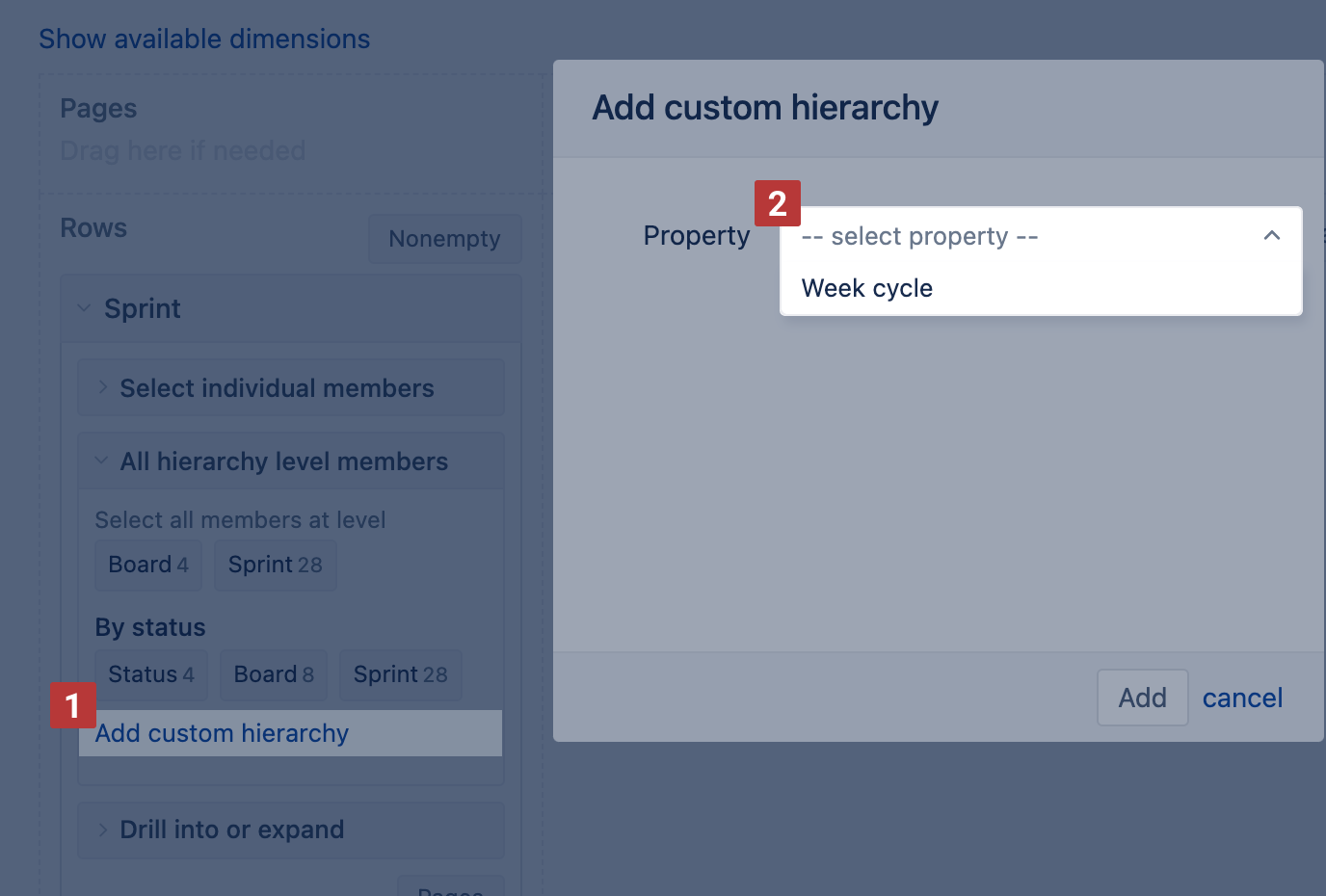
Press "Add". A new Sprint hierarchy by Week cycle is created: under the week cycle are grouped all sprints (across all boards) having the same sprint start date week.
When Sprint custom hierarchy for cycles is in place, adjust standard Jira Software reports for use with sprint cycles.
If the same REST API configuration and sprint property "Week cycle" mapping to the Sprint dimension is done, you may import / export available Sprint by weeks reports (burn-down, velocity, sprint balance) from the eazyBI Demo Training account and use them with your data! Then needed calculated members and measures will be imported as well.
Calculated members in Sprint dimension Week cycle hierarchy
Most of the standard sprint reports are filtered by closed, active, or future sprints. As sprint cycles are collections of sprints, they do not have a dedicated property for their start/end dates or status (active, closed, future), only the date in the cycle name, thus, default Active sprint, Last closed sprints, and other Sprint calculated members can't be used.
Create new calculated members in the Sprint dimension custom hierarchy for retrieving current cycle or last closed cycles (or similar) using available information in the cycle name.
Active (current) sprints
If the sprint cycle name contains the sprint start date, then the active sprint cycle can be detected by that date. If the Week cycle is imported in format "yyWnn, mm dd yyyy", then the following calculated member would extract the cycle start and the last of started cycles will be retrieved as the current cycle.
Aggregate(
Tail(
Filter(
[Sprint.Week cycle].[Week cycle].Members,
--from the sprint cycle name parse the date and find all those that are older than the current date
DateCompare(
Now(),
DateParse(Right([Sprint.Week cycle].CurrentMember.Name, 12))
) >= 0
)
-- then retrieve the last element
).Item(0)
)
Last (previous) sprints
Using a similar approach - the extracted date from the sprint week cycle - create calculated members for last sprint cycles, previous sprint cycles, etc. There is no status for the cycle, therefore, it is complicated to detect whether the cycle is completed.
Last 5 cycles if the cycle name contains a date is detected by dates (five sprints having this date in the past):
Aggregate(
Tail(
Filter(
[Sprint.Week cycle].[Week cycle].Members,
DateCompare(
Now(),
DateParse(Right([Sprint.Week cycle].CurrentMember.Name, 12))
) >= 0
),
5
)
)
Sprints by weeks current cycle story points burn-down report
This chapter describes how to create Sprint Story Points burn-down report for Sprint Week cycles, using Sprint custom hierarchy by Week cycle.
The can be created based on standard Sprint Story Points burn-down report, adding specific measures and changing how the report is filtered.
Measures for sprint cycle (multiple sprints) burn-down report
Create a set of measures to draw a guideline for the sprint cycle (which actually is a compound from multiple sprints).
First, define two measures to calculate the Start and End date of the selected cycle.
The calculation for Multiple Sprints start date that retrieves the earliest start date within the sprints of the cycle
Cache(
TimestampToDate(
Min(
Filter(
-- get all sprints in any selection
DescendantsSet([Sprint].CurrentHierarchyMember, [Sprint].CurrentHierarchyMember.Levels('Sprint')),
-- filter out sprints with Start date that match other report filters as well
NOT IsEmpty([Sprint].CurrentHierarchyMember.Get('Start date'))
),
CASE WHEN
(
[Measures].[Transitions to],
[Time].CurrentHierarchy.DefaultMember
) > 0
THEN
-- Sprint start date to timestamp for Min function
DateToTimestamp([Sprint].CurrentHierarchyMember.Get('Start date'))
END
)
)
)
The calculation for Multiple Sprints end date that retrieves the latest start end within the sprints of the cycle
Cache(
TimestampToDate(
Max(
Filter(
-- get all sprints in any selection
DescendantsSet([Sprint].CurrentHierarchyMember, [Sprint].CurrentHierarchyMember.Levels('Sprint')),
-- filter out sprints with End date that match other report filters as well
NOT isempty([Sprint].CurrentHierarchyMember.Get('End date'))
),
CASE WHEN
(
[Measures].[Transitions to],
[Time].CurrentHierarchy.DefaultMember
) > 0
THEN
-- Sprint start date to timestamp for Min function
DateToTimestamp([Sprint].CurrentHierarchyMember.Get('End date'))
END
)
)
)
Recreate standard "Time within sprint" as Time within multiple sprints for sprint cycle, marking days between the earliest sprint start date to the latest sprint end date.
CASE WHEN
Sum(
Generate(
{
[Sprint].CurrentHierarchyMember,
ChildrenSet([Sprint].CurrentHierarchyMember)
},
Descendants([Sprint].CurrentHierarchyMember, [Sprint].CurrentHierarchy.Levels('Sprint'))
),
CASE WHEN
DateBetween(
[Time].CurrentHierarchyMember.StartDate,
DateAddDays([Sprint].CurrentHierarchyMember.Get('Start date'), -1),
[Sprint].CurrentHierarchyMember.Get('End date')
)
THEN
NonZero(
(
[Measures].[Issues created],
[Time].CurrentHierarchy.DefaultMember
)
)
END
) > 0
THEN
1
END
Now, when you have created measures to define the timeframe for the sprint cycle, create a measure Multiple sprints guideline that takes into account all story points committed to all sprints within the sprint cycle and the line is drawn across the whole time period defined by the measures above.
CASE WHEN
[Measures].[Time within multiple Sprints] > 0
THEN
-- total commited points of all selected sprints
(
[Measures].[Sprint Story Points committed],
[Time].CurrentHierarchy.DefaultMember
)
*
(
DateDiffWorkdays(
DateWithoutTime([Measures].[Multiple Sprints start date]),
DateAddDays(DateWithoutTime([Measures].[Multiple Sprints end date]), 1)
)
-
DateDiffWorkdays(
DateWithoutTime([Measures].[Multiple Sprints start date]),
[Time].CurrentHierarchyMember.NextStartDate
)
)
/
DateDiffWorkdays(
DateWithoutTime([Measures].[Multiple Sprints start date]),
DateAddDays(DateWithoutTime([Measures].[Multiple Sprints end date]), 1)
)
END
Put the burn-down report together
Adjust the standard Sprint burn-down chart report:
- In Pages, select Sprint dimension custom hierarchy by cycles, select calculated member "Active (or Current) cycle" (described above).
- In columns, select measure Time within multiple sprints and set rows filter > 0 by it to display active sprint cycle time frame; then remove the column. Remove Time within sprint >0 filter!
- Remove measure Sprint Story Points guideline, add measure Multiple sprints guideline
- Save as the report as your sprint cycle burn-down chart.
Sprints by weeks velocity
Sprint week cycle velocity based on the Sprint custom hierarchy by Week.
In the sprint velocity chart, there are a few things that are different from the standard velocity chart:
- how to filter last cycles to represent them in the report
- sprint cycle velocity calculation to include cycles that are not yet completed
- running velocity calculation for last closed sprints
Measures for sprint cycle velocity report
Create measures for cycle velocity and running velocity in the previous 5 cycles.
Cycle velocity Sprint Story points Done measure is calculated similarly as in standard velocity chart (based on measure "Sprint Story points completed"), only additionally using measure Story points resolved if cycle sprints are not yet completed and that Sprint Story Points completed measure is not available (as there is no specific marker if the cycle is closed or not).
-- if not completed sprint then show resolved CoalesceEmpty( [Measures].[Sprint Story Points completed], [Measures].[Story Points resolved] )
Running velocity 5 for the last 5 (or more) sprint cycles would use this Sprint Story points Done measure as a velocity.
The Week cycle is in the format "yyWnn, mm dd yyyy", therefore, sprint cycles are automatically ordered by dates. Retrieve the previous 5 (or more/less) members of the same level members and then calculate the average velocity:
Avg(
Tail(
Head(
-- sprints from the same level
[Sprint].CurrentHierarchyMember.Level.Members,
Rank(
[Sprint].CurrentHierarchyMember,
[Sprint].CurrentHierarchyMember.Level.Members
)
),
-- number of sprints to show
5
),
[Measures].[Sprint Story Points done]
)
Put the print cycle velocity report together
Put the report together based on the standard Sprint velocity chart or from scratch (in this case, there is no big difference).
- In rows, select cycle level members from Sprint custom hierarchy
- Filter cycles to display only the latest 10-20 (up to you) cycles.
Create a measure that shows either the start date of an individual sprint or retrieves either a cycle date from the cycle name or the cycle rank based on the naming pattern, and then use this measure in columns to filter the cycles in the report.
In this measure, extract the date section and parse as a date; then use this measure in columns and set a date filter (<, >, =, between).
CASE WHEN
NOT IsEmpty([Sprint].CurrentHierarchyMember.Get('Start date'))
THEN
[Sprint].CurrentHierarchyMember.GetDate('Start date')
ELSE
DateParse(
Right([Sprint].CurrentHierarchyMember.Name, 12)
)
END
3. Add, in columns, measures Sprint Story points committed, as well as just created "Sprint Story points Done" and "Running velocity 5" to show cycle velocity and running velocity.
4. In the bar chart view, adjust colors, as well as set "Running velocity 5" as a line.
5. Save as your velocity chart.
Using a similar approach, you can recreate other Sprint reports.
Sprint cycles by other naming patterns.
You can use not only the sprint start date to create Sprint cycles, but other properties, for instance, the sprint sequence number based on the sprint naming pattern.
Using the same REST API approach, you can import a cycle name extracted from the sprint name if the sprint naming conventions contain some patterns; it could be either a date (or part of the date) or the sequence number.
According to that, you need to adjust the calculations discussed above. Think about how to detect active/last sprints, as well as the previous 5 last sprints to calculate running velocity, as there is no particular date on how to detect past/future cycles.
Calculated members for current and last sprint cycles in Sprint dimension
If the sprint start date can't be detected from the sprint cycle, then active cycles can be retrieved by checking a smaller amount of last cycles by the sequence number and then retrieving those having cycles active sprints (there can be more than one active sprint). The first step (retrieving 10 cycles) is for optimizations purposes! This and the following calculations are for cycle names in the format "Sprint XX" (see ExtractString() part).
Aggregate(
Filter(
-- pick the last 10 cycles by the serial number in the naming pattern
Tail(
Order(
[Sprint.Cycle].[Cycle].Members,
Cast(Replace(ExtractString([Sprint.Cycle].CurrentMember.Name, 'Sprint (\d+).*'), 'Sprint ', '') AS NUMERIC),
ASC
),
10
),
-- filter cycles with active sprints
Count(
Filter(
[Sprint.Cycle].CurrentMember.Children,
NOT [Sprint.Cycle].CurrentMember.GetBoolean('Closed')
AND
IIf(
IsEmpty([Sprint.Cycle].CurrentMember.Get('Status')),
NOT IsEmpty([Sprint.Cycle].CurrentMember.Get('Start date')),
[Sprint.Cycle].CurrentMember.Get('Status') = 'Active'
)
)
) > 0
)
)
Last closed-cycle if the cycle name does not contain any date; then look for 10 latest cycles (by the sequence number in the name) and then check each cycle if they have closed sprints. If there is at least one closed sprint within the cycle, the cycle is treated as closed; the last one from the set is retrieved as the latest closed.
Aggregate(
Tail(
Filter(
-- pick the last 10 cycles by name pattern
Tail(
Order(
[Sprint.Cycle].[Cycle].Members,
Cast(Replace(ExtractString([Sprint.Cycle].CurrentMember.Name, 'Sprint (\d+).*'), 'Sprint ', '') AS NUMERIC),
ASC
),
10
),
-- filter by closed sprints
Count(
Filter(
[Sprint.Cycle].CurrentMember.Children,
[Sprint.Cycle].CurrentMember.GetBoolean('Closed')
)
) > 0
),
-- 1 last (from Tail) closed sprint from a board
1
-- address the first (0) member from a set
).Item(0)
)
Story points burn-down report
Sprint Story Points burn down for Sprint cycles based on the sprint naming pattern (Sprint custom hierarchy by Name)
The report is created similarly to the Sprint Week cycles burn-down report.
Sprint velocity
Sprint cycle velocity based on the sprint naming pattern (Sprint custom hierarchy by Name).
The difference from Sprint Week cycles velocity report is how to detect previous last sprints as well as how to filter the cycles in the report.
There are differences in how to create the Running velocity 5 measure. Sprint cycles are ordered alphabetically (not in their natural order by time), therefore, the ordering must be done in the calculation first (accordingly to the cycle naming pattern) and then retrieved previous 5 for calculating the running velocity. Note that the extraction of the cycle sequence number depends on the cycle naming pattern!
Avg(
Tail(
Head(
Order(
-- order sprints from the same level
[Sprint].CurrentHierarchyMember.Level.Members,
-- extract the number from sprint name and order decreasingly
Cast(Replace(ExtractString([Sprint].CurrentHierarchyMember.Name, 'Sprint (\d+).*'), 'Sprint ', '') AS NUMERIC),
ASC
),
Rank(
[Sprint].CurrentHierarchyMember,
Order(
-- order sprints from the same level
[Sprint].CurrentHierarchyMember.Level.Members,
-- extract the number from sprint name and order decreasingly
Cast(Replace(ExtractString([Sprint].CurrentHierarchyMember.Name, 'Sprint (\d+).*'), 'Sprint ', '') AS NUMERIC),
ASC
)
)
),
-- number of sprints to show
5
),
[Measures].[Sprint Story Points done]
)
To create a measure that helps to filter the cycles, you also need to retrieve the sprint rank. The naming pattern used in Rank() must be the same as that used in Running velocity 5 measure! When you have a measure that returns the sprint rank, use it columns and apply a row filter with (< or > ) function by this measure to limit cycles in the report.
NonZero(
-- get rank in the descresing order of sprints - the last sprints
Rank(
[Sprint].CurrentHierarchyMember,
Order(
-- order sprints from the same level
[Sprint].CurrentHierarchyMember.Level.Members,
-- extract the number from sprint name and order decreasingly
Cast(Replace(ExtractString([Sprint].CurrentHierarchyMember.Name, 'Sprint (\d+).*'), 'Sprint ', '') AS NUMERIC),
DESC
)
)
)
See also
- Learn about different Jira Software measures and dimensions - what they are and how they work.
- See more about options that are available when you create a report.
- Learn how to modify different chart types.
- See training videos to learn more.